
17. April 2023 von Marc Mezger und Dr. Hong Chen
Eine kurze Einführung in GPT4
Eine kurze Historie der GPT-Modelle
GPT steht für Generative Pre-trained Transformer. GPT-4 ist bereits die vierte Generation in der GPT-Modellfamilie, die vom Unternehmen OpenAI entwickelt wurde. OpenAI wurde im Dezember 2015 von einer Gruppe von Tech-Größen wie Elon Musk, Sam Altman, Greg Brockman und Ilya Sutskever gegründet. Das Unternehmen hat es sich zur Aufgabe gemacht, eine sichere und nützliche Künstliche Intelligenz (KI) zu entwickeln, die zur Lösung einiger der dringendsten Probleme der Welt – wie Klimawandel, Armut und Krankheiten – beitragen kann.
Das Unternehmen arbeitet an verschiedenen KI-Technologien – darunter Spracherkennung, Bilderkennung, NLP (Natural Language Processing), Robotik und mehr.
GPT-Modelle haben ihren Ursprung in der Transformerarchitektur. Diese wurde 2017 in einem Beitrag von Vaswani et al. im Paper „Attention is all you need“ vorgestellt. Sie haben sich seitdem aufgrund ihrer Fähigkeit, weitreichende Abhängigkeiten zu verarbeiten, und wegen ihrer Parallelisierbarkeit zu einer beliebten Wahl für Aufgaben der Verarbeitung natürlicher Sprache entwickelt. Zahlreiche bahnbrechende KI-Modelle basieren auf dieser Architektur.
Die erste Iteration, GPT-1, erschien 2018 und zeigte das Potenzial von unüberwachtem Lernen und Pre-Training-Techniken für das Verständnis natürlicher Sprache. GPT-2, das 2019 veröffentlicht wurde, brachte erhebliche Fortschritte bei der Sprachmodellierung mit 1,5 Milliarden Parametern, die kohärente und kontextrelevante Texte erzeugen. OpenAI hielt die vollständige Veröffentlichung aufgrund von Bedenken im Hinblick auf möglichen Missbrauch zunächst zurück.
Im Juni 2020 stellte OpenAI GPT-3 mit unglaublichen 175 Milliarden Parametern vor, was einen wichtigen Meilenstein im KI-Bereich darstellt. GPT-3 zeigte eine bemerkenswerte Leistung bei verschiedenen Aufgaben, wie Übersetzung, Zusammenfassung und Beantwortung von Fragen, und das bei minimaler Feinabstimmung. Der große Umfang schränkte jedoch seine breite Anwendung ein.
Nachfolgende Versionen – einschließlich ChatGPT (der Chatbot) – bauen auf den Kernprinzipien von GPT-3 auf und verfeinern die Fähigkeiten des Modells für eine effektivere Kommunikation und praktische Anwendungen. Diese Entwicklungen haben zu einer weiten Verbreitung von GPT-Modellen in Branchen geführt, die von Kundensupport und Inhaltserstellung bis zu virtuellen Assistenten und Sprachübersetzung reichen.
Was ist GPT-4?
GPT-4 wurde am 14. März 2023 von OpenAI vorgestellt, allerdings war das eigentliche Training von GPT-4 schon Mitte 2022 abgeschlossen. Die Zeit bis zum Release wurde damit verbracht, das Modell für User Alignment und Security zu optimieren.
Leider ist nicht bekannt, wie groß GPT-4 ist. Es wird vermutet, dass es sich um ein Modell mit 100 Trillionen Parametern handelt. Der Größenunterschied zwischen dem Vorgänger GPT-3 und GPT-4 wird in der folgenden Abbildung recht deutlich. Es könnte aber auch sein, dass das Modell ungefähr genauso groß ist, aber mit besseren Daten und länger trainiert worden ist. Bedauerlicherweise wurde dies nicht veröffentlicht. Warum das so ist, beschreiben wir noch im Technical Report.
Kurz gesagt, GPT erzeugt natürlichsprachlichen Text auf der Grundlage von Eingaben und kontextuellen Zusammenhängen mithilfe eines neuronalen Netzes, das auf einer großen Menge von Daten trainiert wurde.
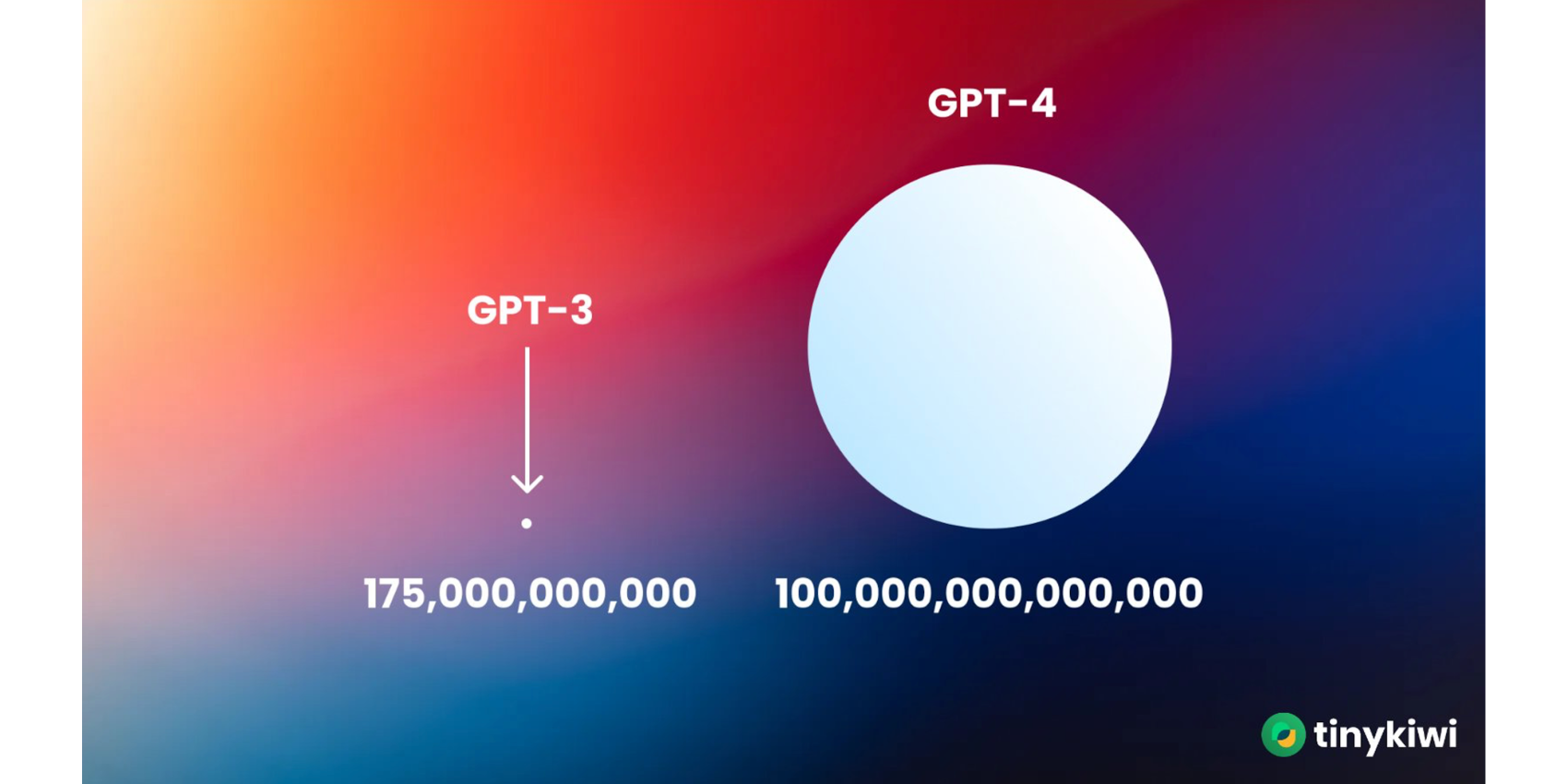
Größenvergleich von GPT-3 und GPT-4, Quelle: tinykiwi
Was ist der Unterschied zu ChatGPT?
Bei der Entwicklung von GPT-4 hat OpenAI großen Wert auf die Sicherheit des Modells gelegt. Ein sicheres KI-Modell ist ein Modell, das so entwickelt wurde, dass es keine unerwarteten oder unerwünschten Ergebnisse liefert, die für Userinnen und User oder die Umwelt schädlich sein könnten. Dies bedeutet, dass das Modell zuverlässig und vorhersehbar sein muss und dass es in der Lage sein muss, Fehleingaben oder böswilligen Angriffen standzuhalten.
GPT-4 kann zusätzlich multimodalen Input akzeptieren. Das heißt, nicht nur Text kann als Input verwendet werden, sondern auch Bilder, auf denen GPT-4 Objekte beschreiben kann.
Die Anwendung macht auch einen Fortschritt in Richtung Mehrsprachigkeit, denn GPT-4 ist in der Lage, tausende Multiple-Choice-Fragen in 26 Sprachen mit hoher Genauigkeit zu beantworten – von Deutsch über Ukrainisch bis Koreanisch.
GPT-4 hat auch ein größeres Gedächtnis für Gespräche. Ein Vergleich: Die Grenze für die Anzahl der Tokens, also die Anzahl der Wörter beziehungsweise Zeichen, die ChatGPT oder GPT-3.5 in einem Durchgang verarbeiten konnten, lag bei 4.096. Das entspricht etwa 8.000 Wörtern. Danach verlor das Modell den Überblick und konnte sich nicht mehr so gut auf frühere Textteile beziehen. GPT-4 hingegen kann 32.768 Tokens verarbeiten. Das bedeutet etwa 64.000 Wörter – genug für eine ganze Kurzgeschichte auf 32 DIN-A4-Seiten.
Grundsätzlich kann festgehalten werden, dass GPT-4 die intelligentere, sicherere und verbesserte Version von ChatGPT ist. Die Anwendung beherrscht im Prinzip alles, was auch ChatGPT kann, nur auf einem höheren Niveau.
GPT-4 Technical Report von OpenAI
Hinsichtlich des Technical Report hat OpenAI lediglich ein sehr oberflächliches Paper über GPT-4 veröffentlicht. Der Grund dafür wird auch explizit genannt: „… given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.“ Da OpenAI quasi zu Microsoft gehört, ist es die KI-Schmiede von Microsoft. Damit ist klar, dass OpenAI keine Forschungseinrichtung mehr ist, sondern eine Softwarefirma. Dennoch möchten wir kurz die wichtigsten Punkte vorstellen.
Interessanterweise werden Modelle wie GPT-4 jetzt mehr an menschlichen Benchmarks getestet und unterliegen weniger wissenschaftlichen Tests. Ein Beispiel hierfür sind Tests wie die Anwaltsprüfung (Bar Exam) in den USA, der SAT, ein standardisierter Test für Studierende, um an Universitäten aufgenommen zu werden, und andere. Erstaunlicherweise erreichte GPT-4 beim Bar Exam ein Ergebnis wie die besten zehn Prozent der Absolventinnen und Absolventen, während ChatGPT zu den schlechtesten zehn Prozent gehörte.

Abschneiden von GPT-3 und -4 an Eignungstest zur Aufnahme an Universitäten in den USA, Quelle: GPT-4 Technical Report
Die folgende Abbildung zeigt, wie gut auch Bilder von GPT-5 verstanden werden.

Erkennen von Bilder, Quelle: GPT-4 Technical Report
Im Paper wird ausschließlich erwähnt, dass GPT-4 mithilfe von Maskierung und mit Reinforcement Learning with Human Feedback (RLHF) trainiert wurde. RLHF beschreibt eine Art von Verstärkungslernen, bei dem ein Agent – etwa eine KI – Feedback von menschlichen Fachleuten erhält, um die Entscheidungen zu verbessern. Das Feedback kann beispielsweise in Form von Korrekturen oder Bewertungen erfolgen, die eine Expertin oder ein Experte an den Agenten gibt, um dessen Verhalten zu beeinflussen. RLHF wird oft verwendet, um das Verstärkungslernen schneller und effizienter zu gestalten, indem es menschliche Intuition und Erfahrung nutzt, um den Lernprozess zu lenken.
Das Spannende daran ist, dass die guten Ergebnisse bei den menschlichen Tests vor allem auf das maskierte Pre-Training zurückzuführen sind, also auf den Teil des Trainings, in dem das Netz hauptsächlich Sätze erhält, bei denen die einzelnen Wörter maskiert sind. Bei RLHF wird das Netzwerk besser an die menschliche Kommunikation angepasst. Man könnte also vermuten, dass dieses Vorgehen besser geeignet wäre, um menschliche Tests zu bestehen, aber das Gegenteil ist der Fall. Die Gründe dafür werden im Report nicht erwähnt.
Der Vorteil von RLHF liegt also nicht in der Leistung, sondern darin, dass das Modell für den Menschen einfacher zu handhaben ist. Man braucht also keinen speziell ausgebildeten Prompt Engineer, sondern jeder kann es.
Das Modell weist in bestimmten Bereichen immer noch Schwächen auf. So waren die Outputs oft zu vage, um brauchbar zu sein, ergaben unpraktische Lösungen oder neigten zu sachlichen Fehlern. Außerdem war die Wahrscheinlichkeit größer, dass längere Antworten Ungenauigkeiten enthielten. Der Bericht stellt auch fest, dass das Modell eher eine vage oder ungenaue Antwort lieferte, wenn es um mehrstufige Anweisungen für die Entwicklung eines radiologischen Geräts oder einer biochemischen Verbindung ging. Es ist jedoch wichtig, darauf hinzuweisen, dass diese Einschränkungen für bestimmte Bereiche und Kontexte spezifisch sind und nicht unbedingt für alle Anwendungsfälle gelten. Dennoch konnte GPT-4 diese als Halluzinationen bezeichneten erfundenen Aussagen reduzieren.
Risiko und Mitigations
Besonderen Wert hat OpenAI bei der Entwicklung von GPT-4 darauf gelegt, die Sicherheit und das Alignment zu verbessern. Der Grund hierfür ist, GPT-4 besser für den kommerziellen Einsatz vorzubereiten. Schließlich bietet das Modell durch diese Maßnahmen deutlich weniger problematische Antworten an. Adversiales Testen und eine eigene Model Safety Pipeline waren die beiden Maßnahmen, die durchgeführt wurden.
Adversiales Testen ist eine Technik des Softwaretestens, bei der versucht wird, Fehler und Schwachstellen im System durch gezielte Angriffe und unerwartete Eingaben zu identifizieren. Dabei soll das System unter Bedingungen getestet werden, die es normalerweise nicht erwarten würde, und somit sollen mögliche Sicherheitsrisiken oder Fehler aufgedeckt werden. Adversiales Training kann bei Large Language Models angewendet werden, indem gezielt gestörte oder verfälschte Daten als Input verwendet werden. So wird das Modell widerstandsfähiger gegen Angriffe und seine Robustheit verbessert sich.
Zu diesem Zweck hat OpenAI mehr als 50 Fachleute engagiert, die mit dem Modell über längere Zeit interagierten und es testeten. Die Empfehlungen und Trainingsdaten dieser Expertinnen und Experten wurden dann wieder verwendet, um das Modell zu optimieren. Als Beispiel wird im Report erwähnt, dass GPT-4 jetzt eine Antwort verweigert, wenn es gefragt wird, wie man eine Bombe baut.
Außerdem wurde eine Model-assisted Safety Pipeline entwickelt, um die Probleme des Alignments besser zu lösen. Im Prinzip ist GPT-4 wie ChatGPT abgestimmt auf RLHF. Allerdings kann selbst nach RLHF noch unsicherer Output von den Modellen erzeugt werden. OpenAI umgeht dieses Problem, indem es GPT-4 verwendet, um GPT-4 zu korrigieren. Der Ansatz besteht darin, zwei Komponenten zu verwenden: zusätzliche RLHF-Trainingsprompts mit sicherheitsrelevanten Inhalten und regelbasierte Belohnungsmodelle (RBRMs). RBRMs sind Zero-Shot-GPT-4-Klassifikatoren, die eine zusätzliche Quelle für Belohnungssignale für das Modell darstellen, um das gewünschte Verhalten zu fördern, zum Beispiel die Generierung harmloser Inhalte und die Vermeidung schädlicher Inhalte. Die RBRMs erhalten drei Eingaben: den Prompt (die Anfrage der Userin oder des Users), den Output des Policy Models und eine von Menschen geschriebene Rubrik (ein Regelwerk in Multiple-Choice-Form), um den Output zu bewerten. Basierend auf diesen drei Eingaben klassifiziert das RBRM den Inhalt mithilfe der Rubrik. Diese Klassifizierung ermöglicht es, das Modell zu belohnen, wenn es die Antwort korrekt verweigert oder eine detaillierte Antwort auf eine harmlose Anfrage gibt. Die Ergebnisse dieses Ansatzes sind in der folgenden Abbildung dargestellt.

Rate bei inkorrekten Verhaltens bei unzulässigen und sensiblen Inhalten, Quelle: GPT-4 Technical Report
Rate des inkorrekten Verhaltens bei unzulässigen und sensiblen Inhalten, Quelle: GPT-4 Technical Report
Bemerkenswert ist, dass die Fortschritte bei den sensiblen Prompts sehr hoch sind, während die Fehlerwahrscheinlichkeit bei den verbotenen Prompts gegen null geht. Dies ist sehr erfreulich, da es zwar nicht möglich ist, alle Fehler zu vermeiden, aber die Fehlervermeidung deutlich optimiert werden konnte.
GPT-4 im Vergleich zu LLaMA
LLaMA ist ein Foundation Model von Facebook AI Research (FAIR) und besonders, weil es eine Sammlung von Foundation Language Models mit 7 bis 65 Milliarden Parametern vorstellt, die mit Milliarden von Tokens trainiert wurden. Was LLaMA einzigartig macht, ist, dass diese Anwendung zeigt, dass es möglich ist, hochmoderne Modelle ausschließlich mit öffentlich zugänglichen Datensätzen zu trainieren, ohne auf proprietäre und unzugängliche Datensätze zurückzugreifen. Dies steht im Gegensatz zu OpenAI und GPT-4. Insbesondere LLaMA-13B übertrifft GPT-3 (175B) in den meisten Benchmarks. Darüber hinaus kann LLaMA-65B mit den besten Modellen, Chinchilla-70B und PaLM-540B, konkurrieren.
Wir glauben, dass dieses Modell dazu beitragen wird, den Zugang zu und das Studium von großen Sprachmodellen zu demokratisieren, da es auf einer einzigen GPU laufen kann. Das Fantastische daran ist, dass LLaMA besser als GPT-3 ist, aber nur zehn Prozent der Größe benötigt, was es viel billiger und einfacher zu benutzen macht. Im Moment ist LLaMA noch etwas schlechter als GPT-4, aber es hat auch noch nicht die Größe von GPT-4 erreicht. Es bleibt also abzuwarten, wie gut die nächste Generation von LLaMA sein wird.

Größenvergleich der unterschiedlichen Modelle, Quelle: https://dataconomy.com/2023/02/best-large-language-models-meta-llama-ai/
Das Interessante dabei ist, dass LLaMA deutlich kleiner ist, aber mit mehr Daten trainiert wurde – eine Möglichkeit, die vielleicht auch für GPT-4 eingesetzt wurde.
Genauere Benchmarks könnt ihr auf diesen Webseiten finden:
Ausblick
GPT-4 ist ein großer Schritt vorwärts in der Leistungsfähigkeit von Sprachmodellen und könnte in vielen Anwendungen nützlich sein. Leider hat sich OpenAI durch die Fokussierung auf das Produkt von seinem Ursprung, der Forschung, entfernt. Es ist daher schwierig zu verstehen, was genau in GPT-4 passiert. Das erschwert auch den Einsatz, da die Anwendung als Black Box verwendet werden muss. Nichtsdestotrotz gibt es schon sehr interessante Anwendungsmöglichkeiten und es wird bereits in einige Produkte integriert.

Beispiele für die Integration von GPT-4 in bestehende Produkte, Quelle: https://openai.com/product/gpt-4
Wer GPT-4 ausprobieren möchte, kann das mit ChatGPT Plus machen. Ein weiteres interessantes Produkt mit GPT-4 wird übrigens GitHub Copilot X sein. Dabei handelt es sich um einen digitalen Assistenten, der auf Coding optimiert ist und mit dem sowohl mit Text- als auch mit Voice-Eingabe interagiert werden kann.
